


Overview
In today’s AI-driven world, the most advanced analytics and AI applications must rely on trusted, consistent, and well-structured data. The backbone of a strong data foundation is a robust data quality framework.
Thus, the purpose of this article is to showcase our Data Quality Framework in Matillion – a scalable, metadata-driven solution designed to ensure your data is always delivered accurately downstream. The framework supports 4 data quality checks:
- Not Null
- Uniqueness
- Domain
- Range
Folder Structure
For each type of data quality check, a separate sub-folder is created where each sub-folder has 2 pipelines:
- <check-name>_Check: Contains the main logic to perform the particular data quality check.
- main_pipeline: Reads the metdata table for a particular check and call the “<check-name>_Check” pipeline.
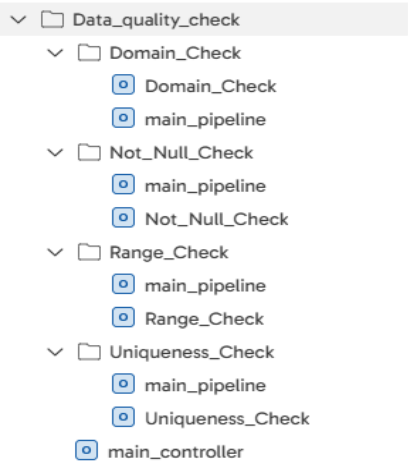
Lastly, we have ‘main_controller’ pipeline that is the parent pipeline that call the ‘main_pipeline’ from sub-folders.
Not Null DQ Check
Purpose
The purpose of this check is to ensure a specific column in a dataset does not contain any missing or null values. This is crucial for maintaining data completeness, especially when certain fields are required for analysis, reporting, or downstream processing.
Job Details
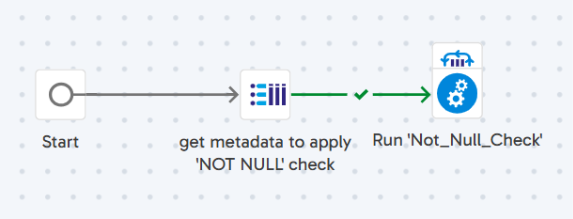
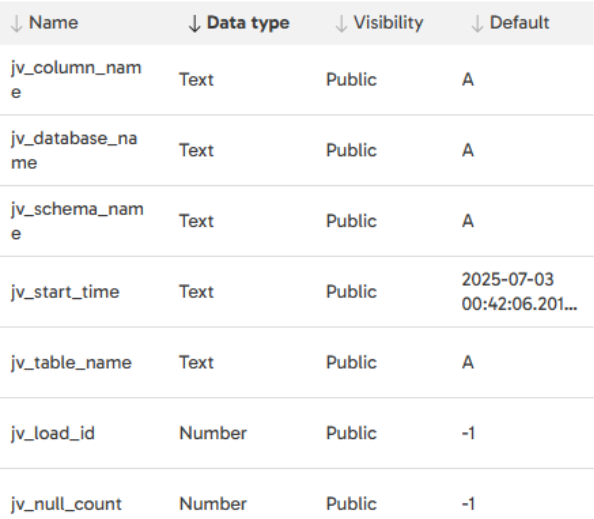
The first step is to use Query Result to Grid to get metadata to apply to the ‘NOT NULL’ check. The purpose of this step is to fetch the metadata from a metadata table where “check_type” = “NOT NULL” and stores the result into ‘gv_columns_to_check’.
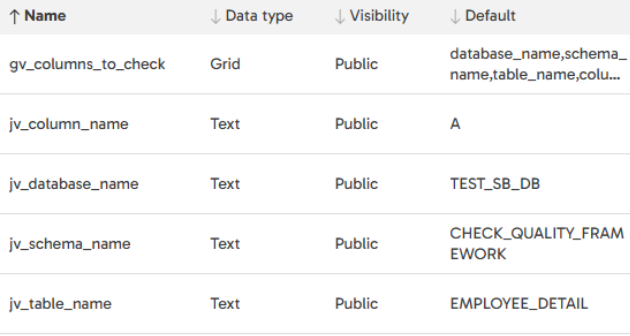
Here are the variables used within this pipeline:
The second steps is to run the ‘Not_Null_Check’ orchestration job where we iterate over ‘gv_columns_to_check’ variable and run the “Not_Null_Check” pipeline concurrently.
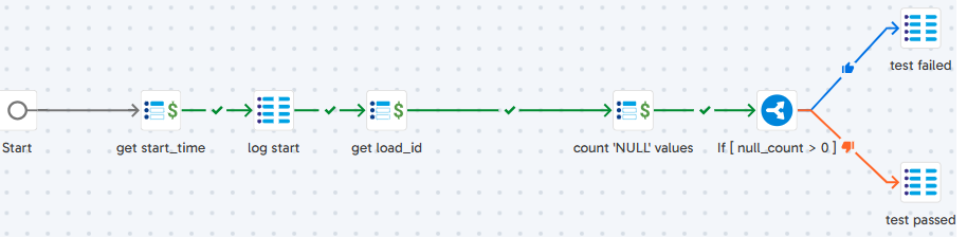
The steps of the ‘Not_Null_Check’ job are as follows:
- get start_time: Store the current timestamp into ‘jv_start_time’.
- log start: Store the pipeline run details into the log table.
- get load_id: Fetch the “load_id” from log table & stores into ‘jv_load_id’.
- count ‘NULL’ values: Count the NULL values in the column of a table & stores result in ‘jv_null_count’.
- test failed: Set the status as ‘FAIL’ into log table when ‘jv_null_count’ > 0.
- test passed: It sets the status as ‘PASS’ into log table when ‘jv_null_count’ = 0.
Here are the variables for the ‘Not_Null_Check’ job:
Uniqueness DQ Check
Purpose
The purpose of this check is to ensure the values in a specific column (or combination of columns) are distinct—meaning no duplicates exist. This is essential for maintaining data integrity, especially when the column serves as a primary key, business identifier, or reference key.
Job Details
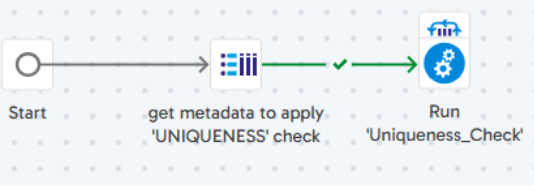
The first step is to use Query Result to Grid to get metadata to apply to the ‘UNIQUENESS’ DQ check. It fetches the metadata from metadata table where “check_type” = “UNIQUENESS” and stores the result into ‘gv_columns_to_check’.
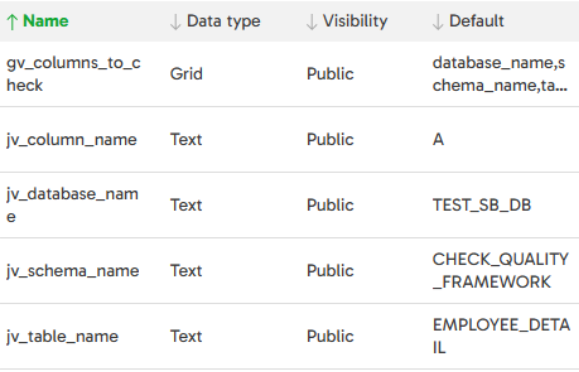
Here are the additional variables within the pipeline:
The second step is to run the Run ‘Uniqueness_Check’ orchestration job to iterate over ‘gv_columns_to_check’ and run the “Uniqueness_Check” pipeline concurrently.
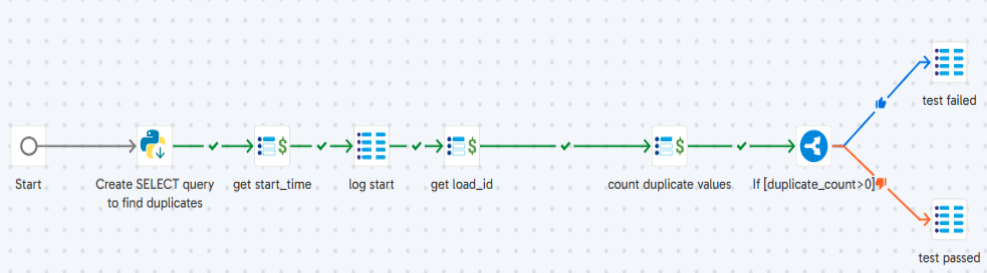
The steps of the ‘Run Uniquiness Check’ job is as follows:
- Create SELECT query to find duplicate: Build the SELECT query to find the duplicates in a column of a table. It’s also capable to build the query for composite uniqueness.
- get start_time: Store the current timestamp into ‘jv_start_time’.
- log start: Store the pipeline run details into the log table.
- get load_id: Fetch the “load_id” from log table & stores into ‘jv_load_id’.
- count duplicate values: Execute the SELECT query that we have built previously to count the duplicate values. Result is stored in ‘jv_duplicate_count’.
- test failed: Set the status as ‘FAIL’ into log table when ‘jv_duplicate_count’ > 0.
- test passed: Set the status as ‘PASS’ into log table when ‘jv_duplicate_count’ = 0.
The variables of the ‘Run Uniquiness Check’ job are:
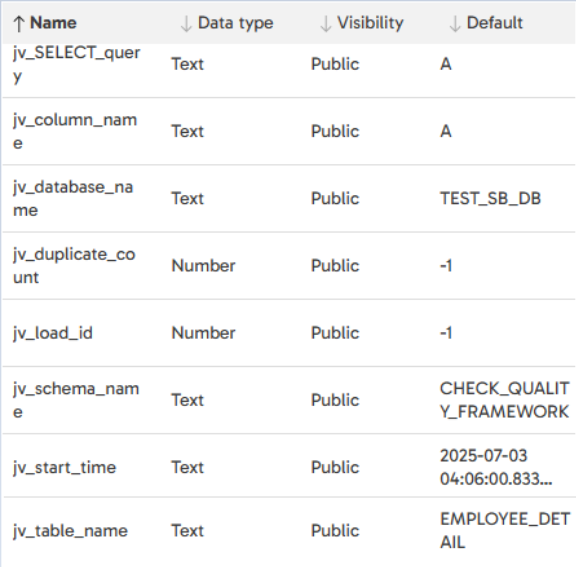
Domain DQ Check
Purpose
The purpose of this DQ check is to ensure that the values in a column fall within a predefined set of acceptable values (also known as the column’s “domain”). This is crucial for maintaining data validity and preventing unexpected or erroneous entries.
Job Details
The first step is to use Query Result to Grid to get metadata to apply ‘DOMAIN’ check where it fetches the metadata from metadata table where “check_type” = “DOMAIN” and stores the result into ‘gv_columns_to_check’.
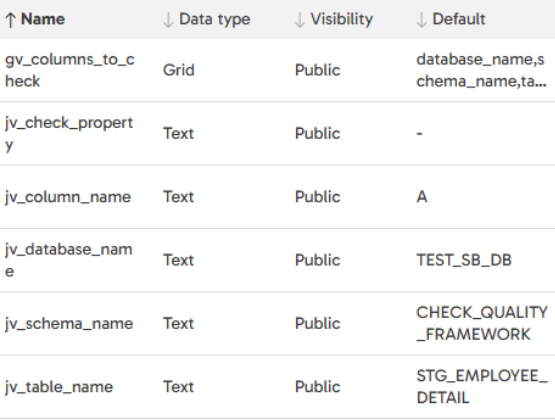
The variables of this pipeline are:
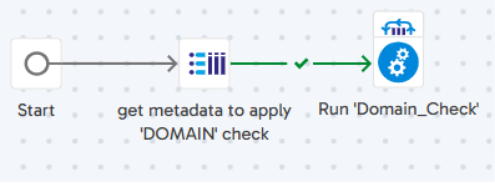
The second step is to rune the ‘Domain_Check’ orchestration job and iterate over ‘gv_columns_to_check’ and runs the “Domain_Check” pipeline concurrently.
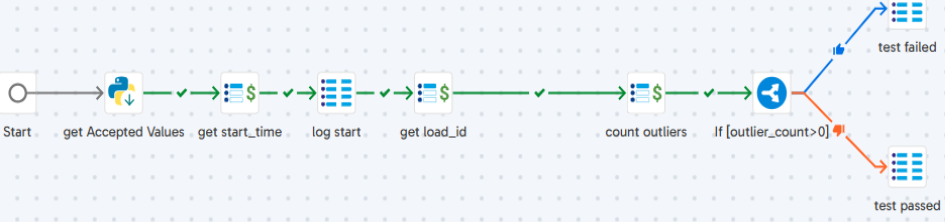
The steps of the ‘Domain Check’ job are:
- get Accepted Values: Receives the accepted values(taken from gv_columns_to_check) and stores the result in “jv_accepted_values”.
- get start_time: Store the current timestamp into ‘jv_start_time’.
- log start: Store the pipeline run details into the log table.
- get load_id: Fetch the “load_id” from log table & stores into ‘jv_load_id’.
- count outliers: Count the values in column that are not in “jv_accepted_values” and stores the result in “jv_outlier_count”.
- test failed: Sets the status as ‘FAIL’ into log table when ‘jv_outlier_count’ > 0.
- test passed: Sets the status as ‘PASS’ into log table when ‘jv_outlier_count’ = 0.
Here are the underlying variables of the ‘Domain Check’ job:
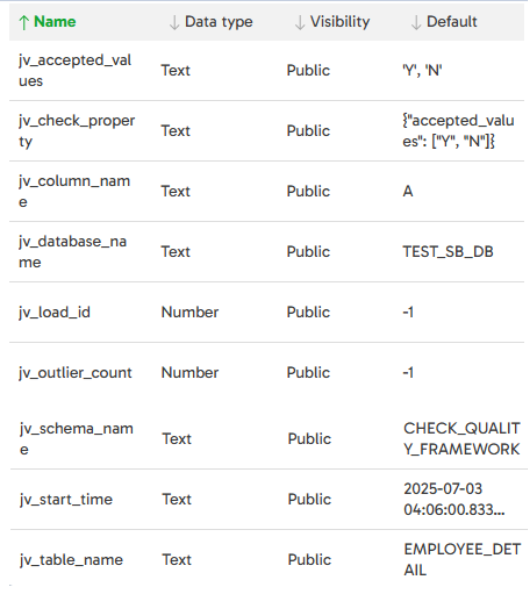
Range DQ Check
Purpose
The purpose of this DQ check is to ensures that numeric values in a column fall within a defined minimum and maximum boundary. This is a way to catch outliers, errors, or values that simply don’t make sense in the context of your data.
Job Details

The first step is to use the Query Result to Grid component to get metadata to apply ‘RANGE’. The purpose of this is to fetch the metadata from a metadata table where “check_type” = “RANGE” and stores the result into ‘gv_columns_to_check’.
The variables of this job are:
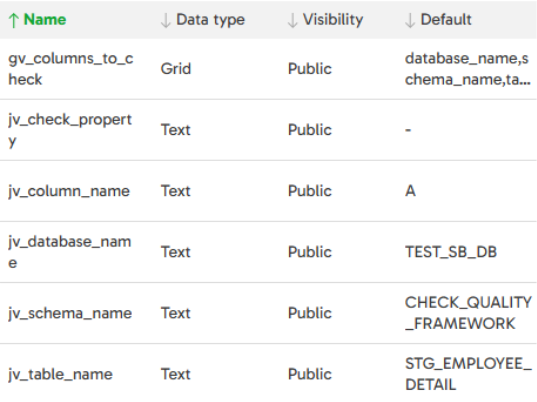
The second step is Run ‘Range_Check’ orchestration job to iterate over ‘gv_columns_to_check’ and run the “Range_Check” pipeline concurrently.
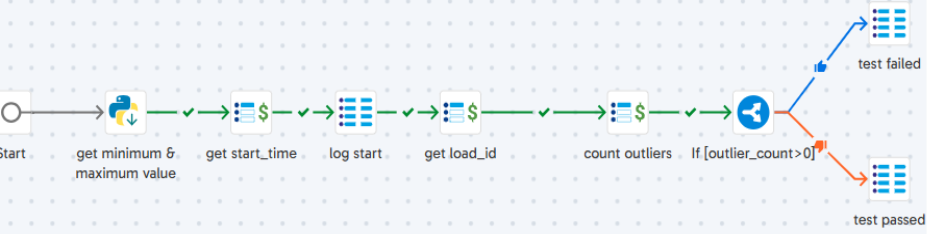
The steps of the ‘Range Check’ job are:
- get minimum & maximum value: Fetches the minimum & maximum value(taken from gv_columns_to_check) and stores the result in ‘jv_min_val’ & ‘jv_max_val’ respectively.
- get start_time:Stores the current timestamp into ‘jv_start_time’.
- log start: Stores the pipeline run details into the log table.
- get load_id: Fetch the “load_id” from log table & stores into ‘jv_load_id’.
- count outliers: Counts all the values in a column outside the range [jv_min_val, jv_max_val] & stores the result in ‘jv_outlier_count’.
- test failed: Sets the status as ‘FAIL’ into log table when ‘jv_outlier_count’ > 0.
- test passed: Sets the status as ‘PASS’ into log table when ‘jv_outlier_count’ = 0.
The variables used in this job are:
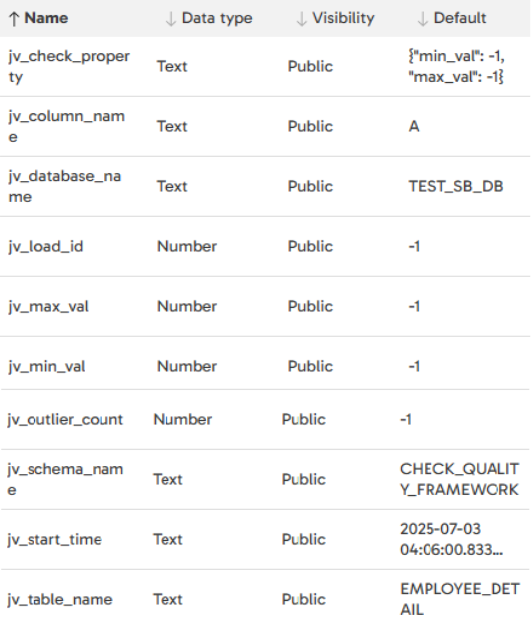
Main Controler
Purpose
The purpose of this parent orchestration job is to run all the data quality checks.
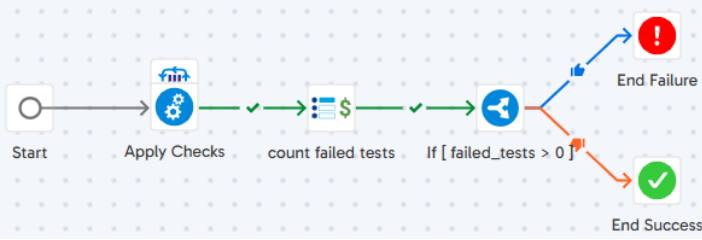
Details
The steps of the ‘Main Controller’ job are:
- Apply Checks: Call the “main_pipeline” of each data check sub-folder concurrently.
- count failed tests: Counts the tests from log table whose status = ‘FAIL’ & stores the result in ‘jv_failed_tests’.
- End Failure: It represents that pipeline has failed when ‘jv_failed_tests’ > 0.
- End Success: It represents that pipeline has succeeded when ‘jv_failed_tests’ = 0.
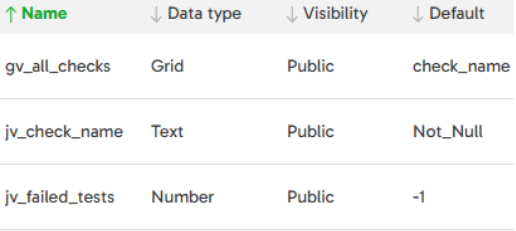
The variables used in this job are:
Summary
The article outlines a metadata-driven Data Quality Check Framework in Matillion that automates four key validations—Not Null, Uniqueness, Domain, and Range—to ensure data accuracy, consistency, and completeness. Using a centralized metadata table and a main controller pipeline, the framework enables scalable, automated, and auditable quality checks across multiple datasets.
If you’re needing to increase your data quality framework, connect with a Matillion expert today.

Comments are closed