


Overview
This article outlines the technical details for a robust Salesforce to Snowflake pipeline using Matillion Data Productivity Cloud (DPC).
Though this framework can be extended to any source, the purpose of this step-by-step guide is to showcase how to load data from Salesforce to Snowflake.
How the Data Flow Works
Start: Generate a unique job_run_id and identify all ready objects.
For Each Object:
- Dynamically build a SOQL query.
- Load data into a temporary Snowflake table (TMP).
- Compare against the target table (EXT).
- Add missing columns on-the-fly.
- Insert only new or changed records.
- Update the watermark for incremental loads.
- Log the result (success or failure).
This logic ensures a resilient, self-healing pipeline that can adapt to changes in Salesforce schemas without manual intervention.
Matillion Job Details
The framework consists of three key Matillion Orchestration Jobs:
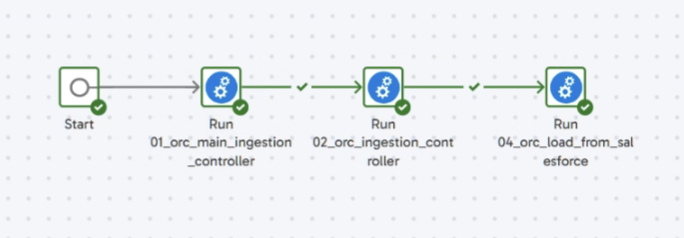
| Job Name | Purpose |
| 01_main_ingestion_controller | Top-level controller for initiating ingestion, generating run IDs, and managing object-level execution. |
| 02_ingestion_controller | Handles the orchestration of object-specific ingestion by routing to source-specific jobs like Salesforce or RDBMS. |
| load_from_salesforce | Actual data ingestion pipeline for Salesforce objects, including SOQL query generation, load, deduplication, and watermark management. |
Each job coordinates metadata-driven ingestion of Salesforce data into Snowflake, incorporating error handling, dynamic query building, logging, and incremental data handling.
Detailed Job Breakdown
For this section we will break down each of the Matillion jobs focusing on the purpose of the job and the steps within the pipeline.
01_orc_main_ingestion_controller
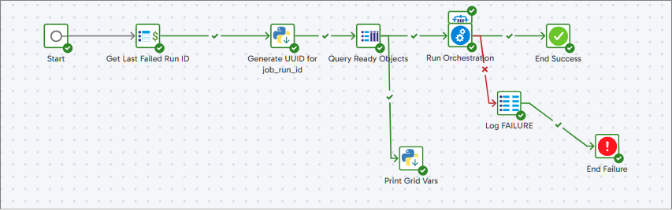
Purpose: Parent job that initiates ingestion by fetching active objects and generating a unique run ID.
Steps:
- Generate job_run_id using UUID
- Identify ready objects from source_objects_rp
- Loop through each object via Table Iterator and call _2_ingestion_controller
02_orc_ingestion_controller
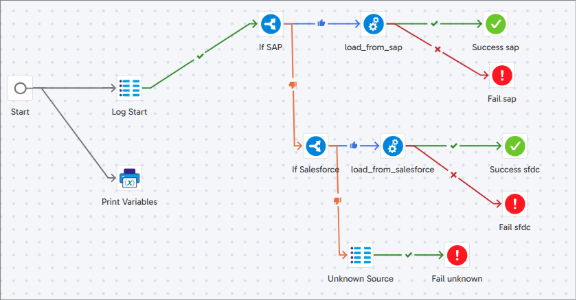
Purpose: Logs the start of ingestion for an object and calls the corresponding load job based on source_type.
Steps:
- Insert ‘STARTED’ entry into ingestion_run_log_rp
- Route to load_from_salesforce if source type is ‘Salesforce’
- On error, call Log Failure
load_from_salesforce
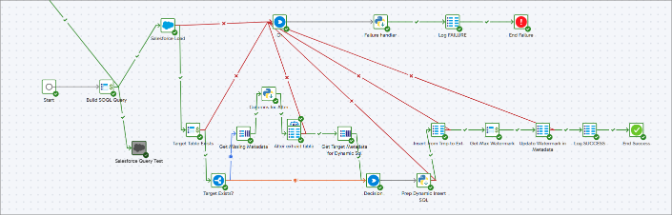
Purpose: Dynamically pulls data from Salesforce using SOQL, handles schema drift, loads to Snowflake, and manages watermark.
Steps:
- Build SOQL Query – Uses metadata and last_watermark_value
- Salesforce Load – Loads into TMP_SFDC_<Object>
- Check Target Table – If not exists → Create
- Get Missing Columns – MINUS query compares TMP vs EXT
- Alter Table – Dynamically adds new columns to EXT
- Insert New Records – Skips existing Ids in EXT
- Update Watermark – Gets max LastModifiedDate
- Log SUCCESS / FAILURE – Inserts status into ingestion_run_log_rp
Variables
| Variable Name | Type | Scope | Description |
| job_run_id | Text | Global | Unique job ID generated per run |
| current_object_id | Integer | Job | ID of current object from metadata |
| sf_object_api_name | Text | Job | Salesforce object name (e.g., Lead) |
| target_table_name | Text | Job | Final table name in Snowflake |
| target_schema | Text | Env | Snowflake schema name |
| target_db | Text | Env | Snowflake database name |
| last_watermark_value | Text | Job | Watermark for incremental extract |
| gv_missing_columns | Grid | Job | Grid of new columns missing in EXT table |
| jv_added_columns_log | Text | Job | Comma-separated list of columns added (for logging) |
| jv_insert_query | Text | Job | Final dynamic insert query |
| jv_error_message | Text | Job | Error message on failure |
| v_records_loaded | Integer | Job | Count of inserted records |
Key Variables
| Variable | Purpose |
| current_object_id | Identifier for the current object being processed. |
| job_run_id | Unique identifier for the overall job run |
| sf_query_string | Dynamically generate SOQL query |
| incremental_column, last_watermark_value, filter_condition | Metadata-driven filters for incremental load |
Error Handling
- All Python and SQL errors are caught and stored in jv_error_message.
- If an object fails, failure is logged in ingestion_run_log_rp without stopping the entire batch.
- OR component after Salesforce Load routes failures gracefully.
- End Failure path terminates cleanly with traceability.
Conclusion
This ingestion framework is robust, metadata-driven and supports parallel execution for Salesforce data sources.
If you’re needing support with your data pipelines, reach out to get connected to our team.

Comments are closed